Firebird/Introduction
From stonehomewiki
Jump to navigationJump to search
Beirf
Use Python to build streaming pipeline
Easy to deploy to Kubernete Cluster
Web UI
Home Page
Home page shows all pipelines. You can see
ID, each pipeline has a unique idNamespace, each pipeline is deployed in a kubernete namespaceImage, the name of the docker image for the pipelineModule, the python module name that contains the main pipeline entry.Running, show if the pipeline is currently running or not.Description, show the description of the pipeline.

Pipeline Page
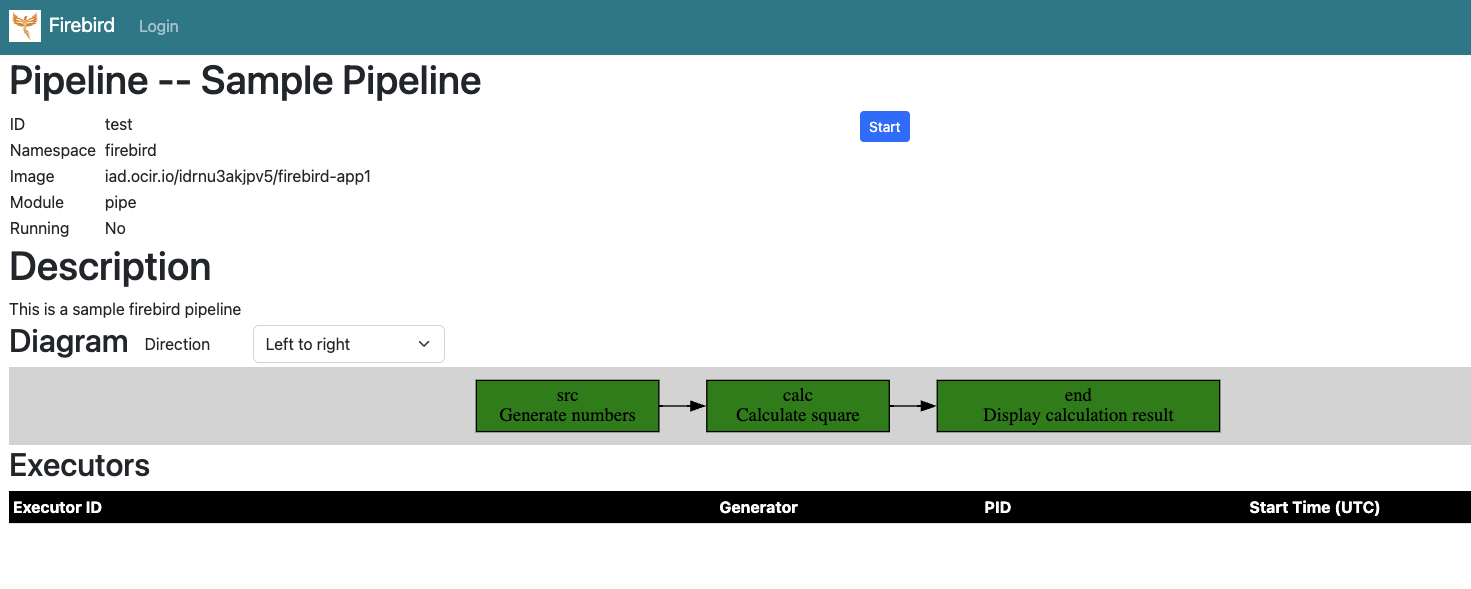
Show the details of a given pipeline. Here is an example:
ID, each pipeline has a unique idNamespace, each pipeline is deployed in a kubernete namespaceImage, the name of the docker image for the pipelineModule, the python module name that contains the main pipeline entry.Running, show if the pipeline is currently running or not.Description, show the description of the pipeline.Diagram, show the topology of the pipeline. You can click each node to see the node details.Executors, if the pipeline is running, you can see the status of each executor.
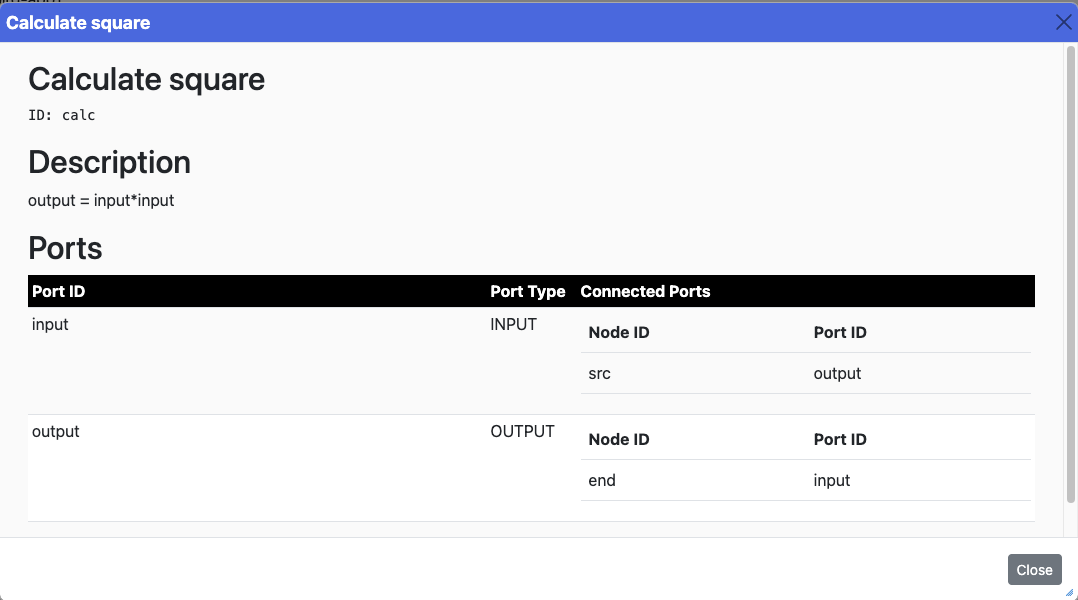
Node dialogbox:
It show the id, title and description of the node. It also shows what are the connected ports, so you the upstream node and downstream node.
- You can click the "Start" button to start the start the pipeline
- You can click the "Stop" button to stop the pipeline